I’ve combined Amy Johnson Crow’s 52 ancestors in 52 weeks challenge, and Steve Little’s The 2025 AI Genealogy Do-Over, to create a unique 52 AI ancestors in 52 weeks party!
52 AI Ancestors in 52 Weeks: Week 47: The Name’s the Same
Introduction
I descend from not one, not two, but five different Nathaniel Brittons – all in a straight line except for one Abraham who clearly didn’t get the memo. On another branch, the Blakes seemed convinced that only two names were worthy of boys: Edward and William. Meanwhile, my Pennsylvania Dutch ancestors preferred naming every male Johan Spiegel. They got creative (sort of) with the middle names.
This week’s theme, “The Name’s the Same,” is a familiar headache for anyone who’s spent time among 18th-century church records or 19th-century census enumerations. Repeating names can turn a straightforward family tree into a knot of mistaken identities.
So how do you avoid merging two different people into one? Or worse, splitting one ancestor into two?
Let’s look at how AI (and a little methodology) can help you keep your people straight.
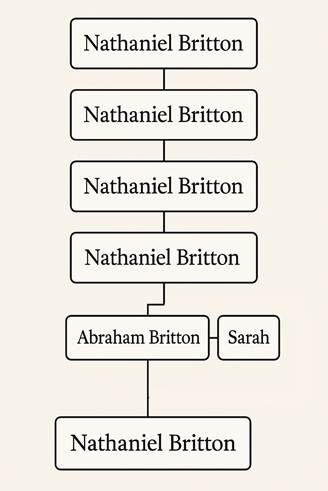
The Foundation: Using the Genealogical Proof Standard
Before we get to the AI shortcuts, let’s talk about the solid, time-tested process that genealogists have used for decades to separate same-name ancestors. The Genealogical Proof Standard (GPS) gives us an approach for making sound conclusions about who’s who.
1. Conduct Reasonably Exhaustive Research
Don’t stop at the first William Blake you find in the 1850 census. Search multiple record types: vital records, census enumerations, land records, probate documents, church records, tax lists, and military records. Look for records in all locations where each person might have lived. Cast a wide net.
The goal isn’t to find every possible record—that’s impossible. But you need enough evidence from enough different sources to see clear patterns emerge.
2. Build an Evidence Analysis Table
This is the old-fashioned version of what we’re going to ask AI to do later. Create a table (or spreadsheet) with these columns:
- Record Date
- Record Type (census, deed, probate, etc.)
- Location (county, town, state)
- Age / Calculated Birth Year
- Spouse Name
- Children in Household
- Occupation
- Associates / Witnesses
- Property Description (adjoining landowners)
Each row represents a different record mentioning the name. As you fill it in, look for patterns. Do some records cluster together with consistent spouse names, children’s names, locations, and occupations? Do others diverge with different family members or different geographic patterns? This visual organization helps you see which records belong to which person.
3. Apply the FAN Principle
FAN stands for Family, Associates, and Neighbors. These connections often provide the key to disambiguation:
- Family: Who are their parents, siblings, children, and other relatives? If two Williams both have fathers named Edward and brothers named Thomas, you might be looking at the same person.
- Associates: Who witnessed their legal documents? Who served as executors of their estates? Who were the godparents of their children? These repeated names across different record types can help you track the right person.
- Neighbors: Who lived next door in census records? Who owned adjoining land in property descriptions? If William Blake consistently appears near the same families across multiple census years, and those same families show up as his neighbors in land records, you’re building a strong case for identity.
4. Look for Unique Identifiers
Some clues are particularly valuable for separating same-name ancestors:
- Middle names or initials: Even just a middle initial can distinguish William A. Blake from William T. Blake.
- Occupation consistency: If your William is listed as a carpenter in 1850, a carpenter in 1860, and a carpenter in 1870, that’s a strong pattern. Another William who’s a farmer is probably a different person.
- Land descriptions: Property records often identify adjoining landowners. If William Blake’s land is described as bordering Thomas Smith’s property in multiple transactions, and you see Thomas Smith witnessing William’s will, you’re building a reliable network.
- Migration patterns: Track geographic movement over time. Did your William move from Vermont to Ohio around 1830? That migration path, combined with other evidence, helps separate him from the William who stayed in Vermont his entire life.
- Military service: Pension records, muster rolls, and military service records often include unique details like unit numbers, service dates, and physical descriptions that can definitively separate two men with the same name.
5. Resolve Conflicting Evidence
Not every piece of evidence will fit perfectly. Ages are often inconsistent across records. Locations might vary slightly. The question is: given all the evidence you’ve collected, which interpretation makes the most sense?
For example, if a William Blake appears in Vermont in 1850 aged 48, and again in 1860 aged 62, you have a 12-year gap versus a 10-year gap between censuses. But if both records show the same wife name, the same children with appropriate age progression, and the same occupation, the weight of evidence suggests it’s the same person and the enumerator probably estimated his age in one or both censuses.
Document your reasoning. When you conclude that two records refer to the same person (or different people), write out why. This forces you to think critically about the evidence and creates a record you can revisit if new information emerges.
Why This Matters
The Genealogical Proof Standard isn’t just academic busywork. It’s the foundation that keeps us from making costly mistakes—like merging two different people into one ancestor or splitting a single person’s life into multiple individuals. It ensures our family trees are built on solid evidence rather than hopeful assumptions.
Now, here’s where it gets interesting: this methodical approach takes time. Hours of it. AI tools can help speed up some of these steps while still maintaining the GPS. Let’s see how.
How AI Can Help Untangle Same-Name Ancestors
When the names repeat, the questions matter more than the names. Here are some ways free AI tools can help you sort out who’s who:
1. Compare and Contrast Timelines
Use ChatGPT or another AI tool to build side-by-side timelines for two individuals with the same name.
Try this prompt:
“Create separate timelines for two men named William Blake. One was born in 1795 and lived in Ohio; the other in 1802 and stayed in Vermont. Use these facts…”
AI can help flag inconsistencies, overlaps, and gaps that might suggest you’re dealing with different people, or maybe one person living a much busier life than expected.
2. Summarize Long Records for Clues
Have a land deed or probate document with a name but no clear identity? Paste it into a tool like ChatGPT and ask:
“Can you list the locations, relationships, and key details in this document?”
This quick summary can help distinguish one Edward from another, especially if they had different professions or owned land in different counties.
3. Middle Name Pattern Recognition
In those Johan-heavy lines, middle names were often more than decorative: they were identifiers. Feed a list of male Spiegel names into an AI and ask:
“Which middle names were repeated across generations?”
This might reveal naming patterns tied to specific branches or generations.
Sample disambiguation table
Here’s a sample comparison table showing two fictitious men named Nathaniel Britton. It demonstrates how details (identifiers) like birthplace, spouse, military service, and burial location can help clearly separate individuals with the same name.
| Identifier | Nathaniel Britton A | Nathaniel Britton B |
| Full Name | Nathaniel Britton | Nathaniel Britton |
| Year of Birth | 1765 | 1768 |
| Place of Birth | Staten Island, New York | Monmouth County, New Jersey |
| Spouse’s Name | Sarah Moore | Mary Johnson |
| Children’s Names | John, Elizabeth, Abraham | Samuel, Anna, Nathaniel Jr. |
| Occupation | Blacksmith | Farmer |
| Military Service Details | Served in local militia, 1781 | Revolutionary War service, 1780-1783, NJ Line |
| Census Residence(s) | Richmond County, NY (1790 – 1820) | Monmouth County, NJ (1790 – 1810), moved to Ohio by 1820 |
| Land/Property Descriptions | Owned land near Richmond Church | Purchased land west of Zanesville, OH |
| Middle Name or Initial | No middle name used in records | Middle initial ‘T’ in 1805 deed |
| Religious Affiliation | Dutch Reformed Church | Baptist |
| Associates/Witnesses in Legal Records | Witnessed by Peter Moore, neighbor | Witnessed by Joseph Johnson, brother-in-law |
| Migration Path | Remained in New York entire life | From NJ to Ohio after 1810 |
| Neighbors in Census | Next to Moore family on 1810 census | Neighbor to Thomas White in 1820 census |
| Burial Location | Buried in St. Andrew’s Churchyard, Staten Island | Buried in family plot near Zanesville, Ohio |
Challenge for Readers: Try It Yourself
Here are two exercises to sharpen your same-name detection skills:
Challenge 1: Disambiguate Your Double
Pick a same-name pair from your tree and feed their facts into an AI tool like ChatGPT. Ask it to highlight the differences and possible overlaps. What stands out?
Challenge 2: Build a “Name Collision” Table
Create a table with columns for Name, Birth Year, Spouse, Location, Occupation, and Key Records. Use it to separate, or connect, those tangled ancestors.
Bonus: Use a spreadsheet or AI-generated table to visualize where paths cross or diverge.
Want to Learn More?
If you’re interested in how AI tools can help with family history research, check out:
- Amy Johnson Crow’s “52 Ancestors” Challenge
- Steve Little’s AI Genealogy Do-Over Project
- Board for Certification of Genealogist’s Genealogical Proof Standard
- Genealogical Proof Standard on FamilySearch
Next Week’s Topic: “Family Recipe”
Get your flour-dusted memories and ancestral stewpots ready!
AI Disclosure
This post was created by me with the help of AI tools. While AI helps organize research, the storytelling and discoveries are my own.
